//2019.08.14
#机器学习算法评价分类结果
1、机器学习算法的评价指标一般有很多种,
对于回归问题一般有MAE,MSE,AMSE等指标,而对于分类算法的评价指标则更多:
准确度score,混淆矩阵、精准率、召回率以及ROC曲线、PR曲线等。
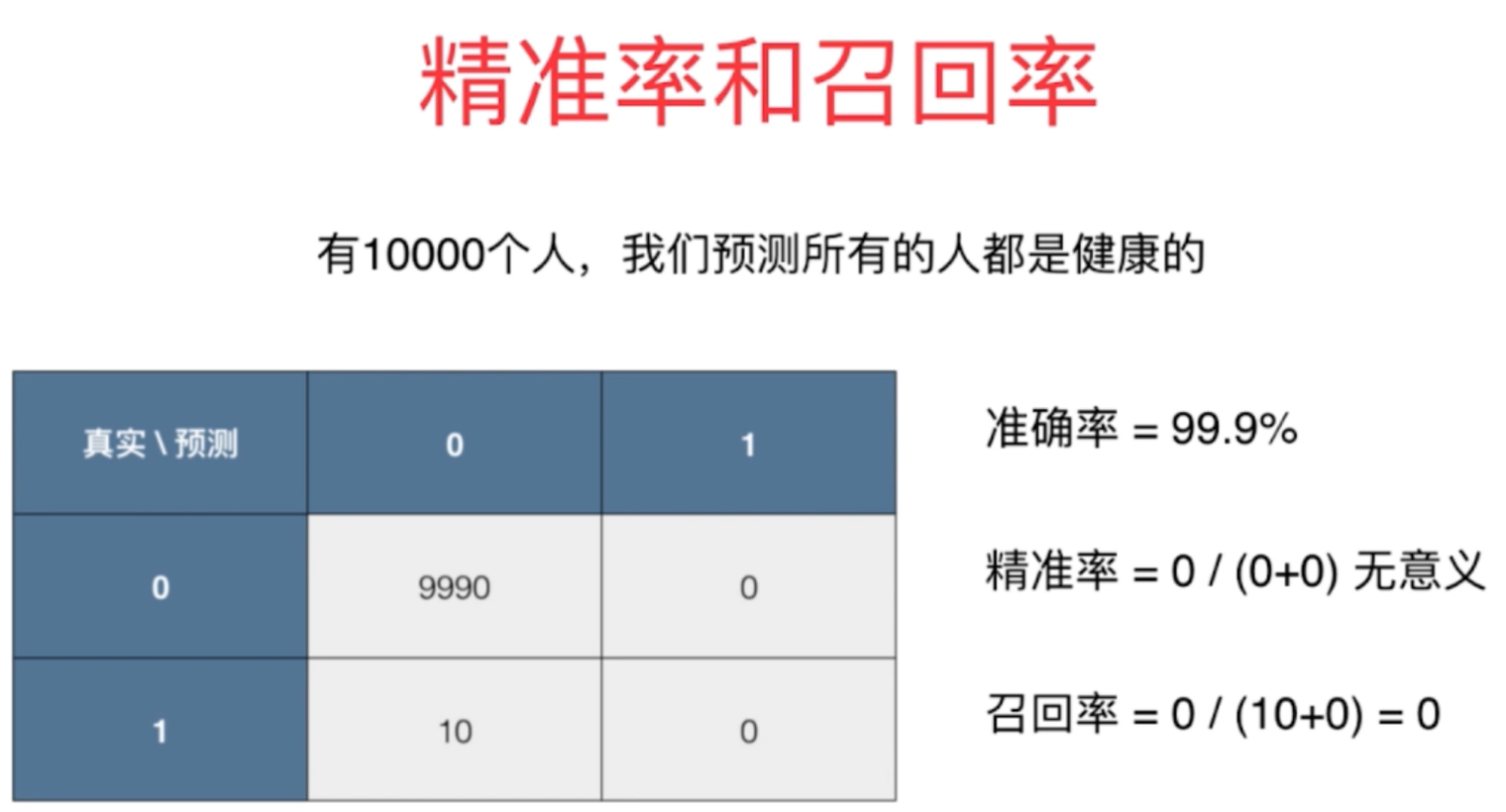
2、对于分类算法只用准确率的评价指标是不够的,并且对于一些情况它是存在问题的,
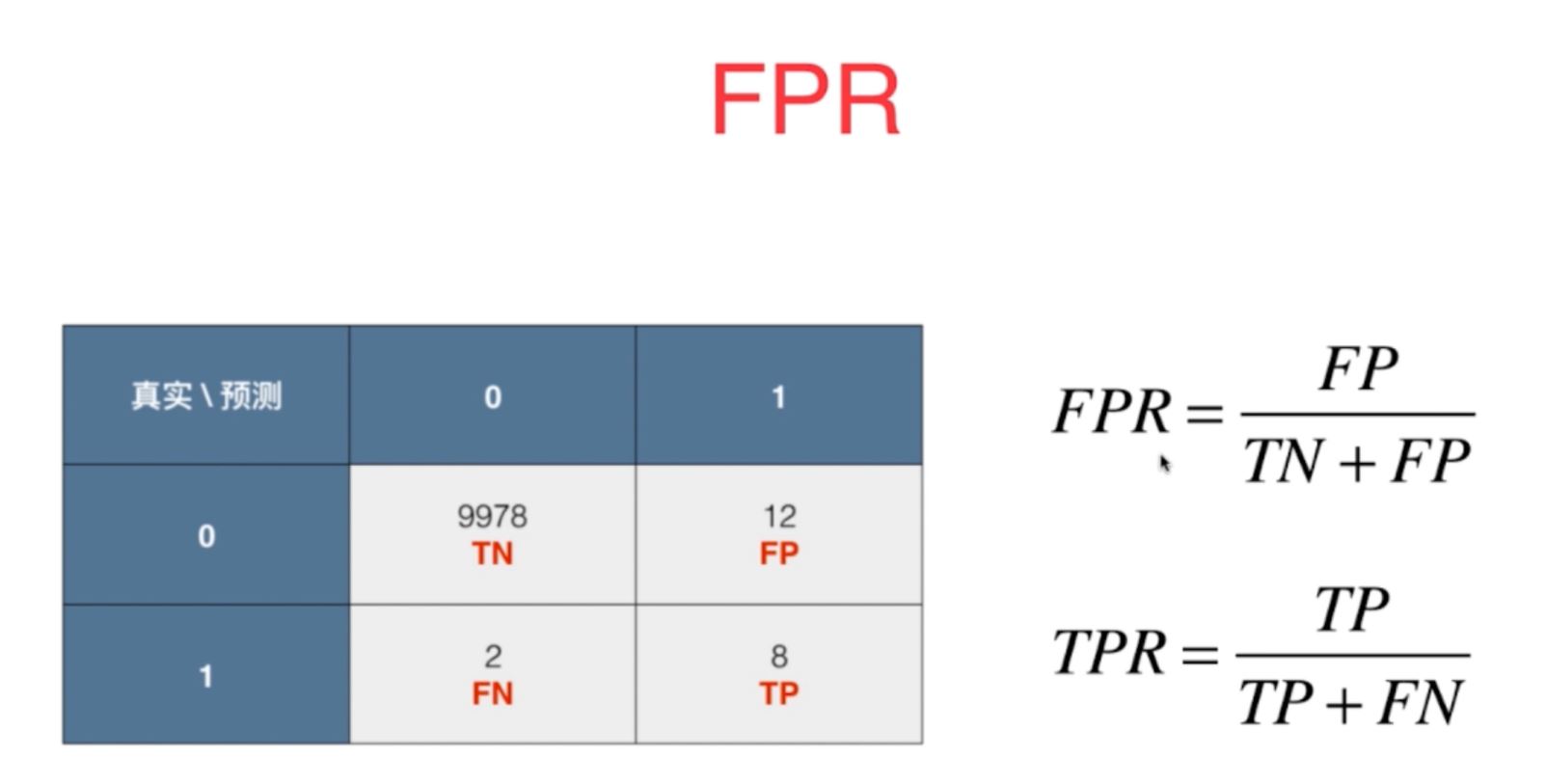
对于极度偏斜的数据集(比如对于癌症的发生预测),准确度的评价指标是存在问题的,需要使用混淆矩阵进行进一步的分析。
3、
混淆矩阵(Confusion Matrix):混淆矩阵的行数和列数一般是由分类算法的分类结果数目决定的,
对于n各分类结果,混淆矩阵是nxn的矩阵,行和列的索引就是n个分类结果,其中行代表真实值,而列代表的是预测值。
矩阵Axy每个网格里的值代表了真实值在x的情况下预测为y的数据样本个数。 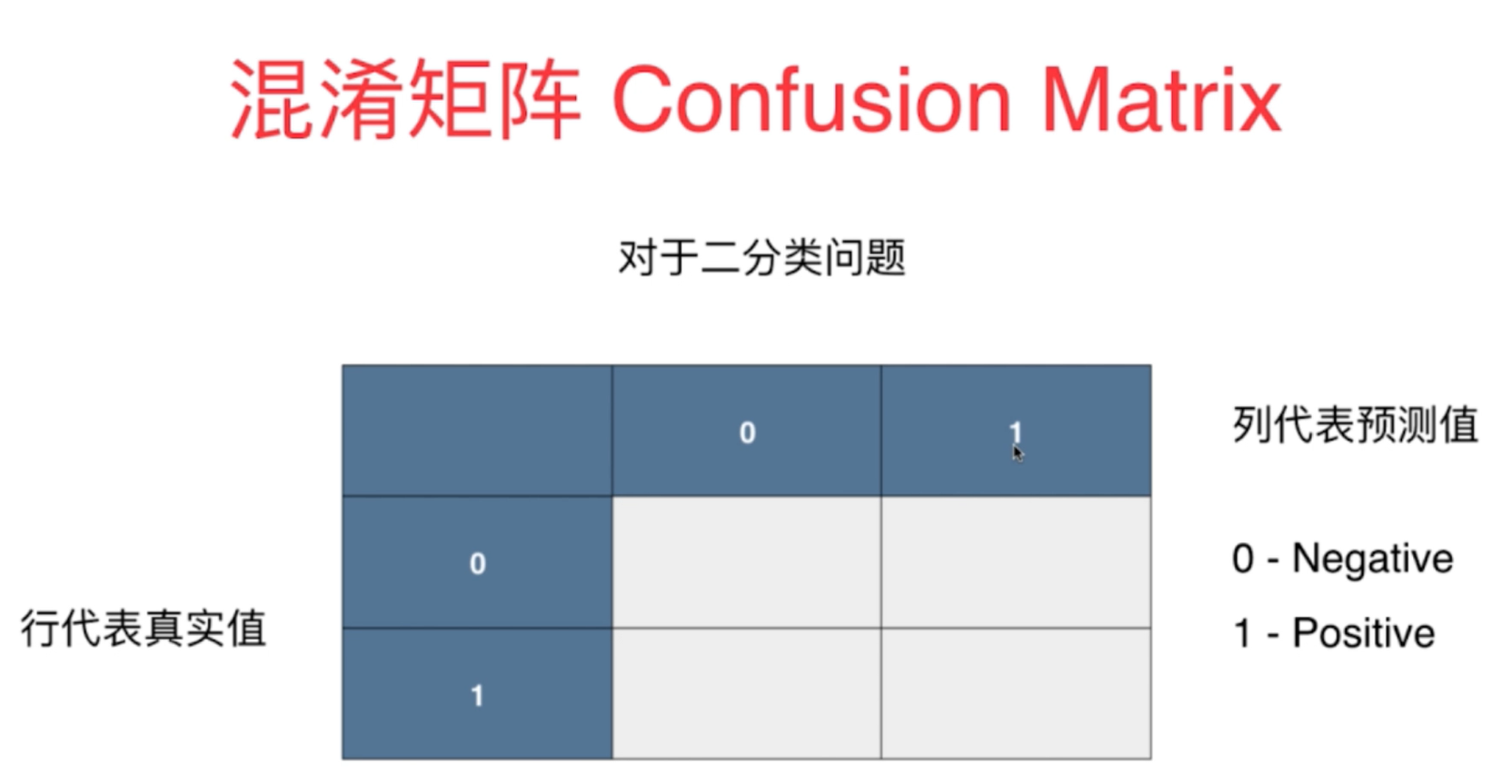
图
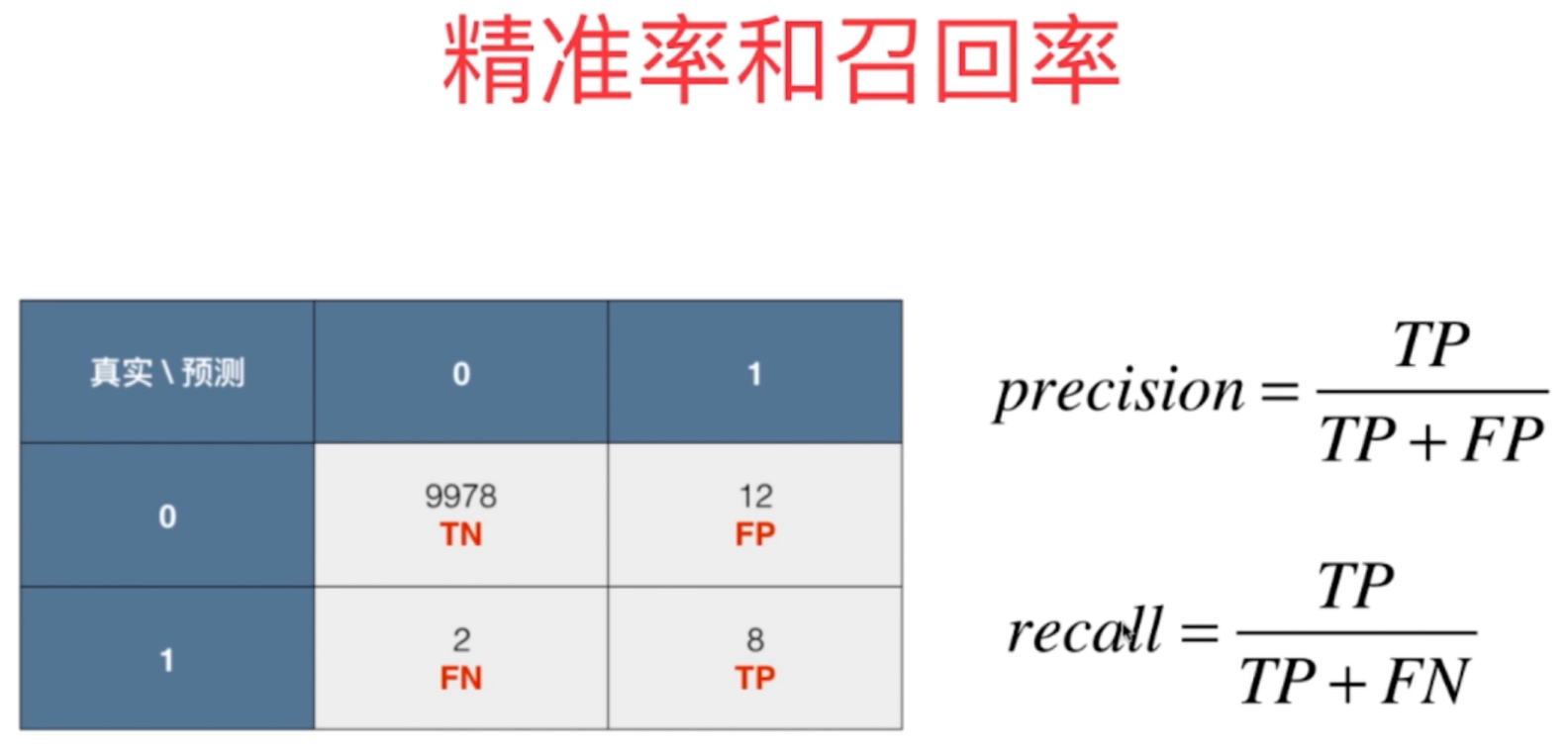
4、根据混淆矩阵得到的矩阵结果,我们可以再次定义两个评价指标,称为
精准率precision和召回率recall,其中
精准率precision=预测正确个数/预测总数,召回率recall=预测正确个数/真实所有个数。
图
5、
精准率和召回率的算法评判指标的解读应该结合具体分析问题的方向和实际场景,不同的场景对于不同指标的侧重点是不一样的。比如在股票预测里面我们更加注重精准率,我们更加注重预测结果的准确度,而召回率低一点意味着我们漏掉了一些希望的结果,而这个影响不大;而在疾病预测里面召回率则更加重要,因为我们更加希望把确实患有疾病的人群检查出来,不想漏掉实际患病的人群,而此时预测的准确率低一点也没有关系。
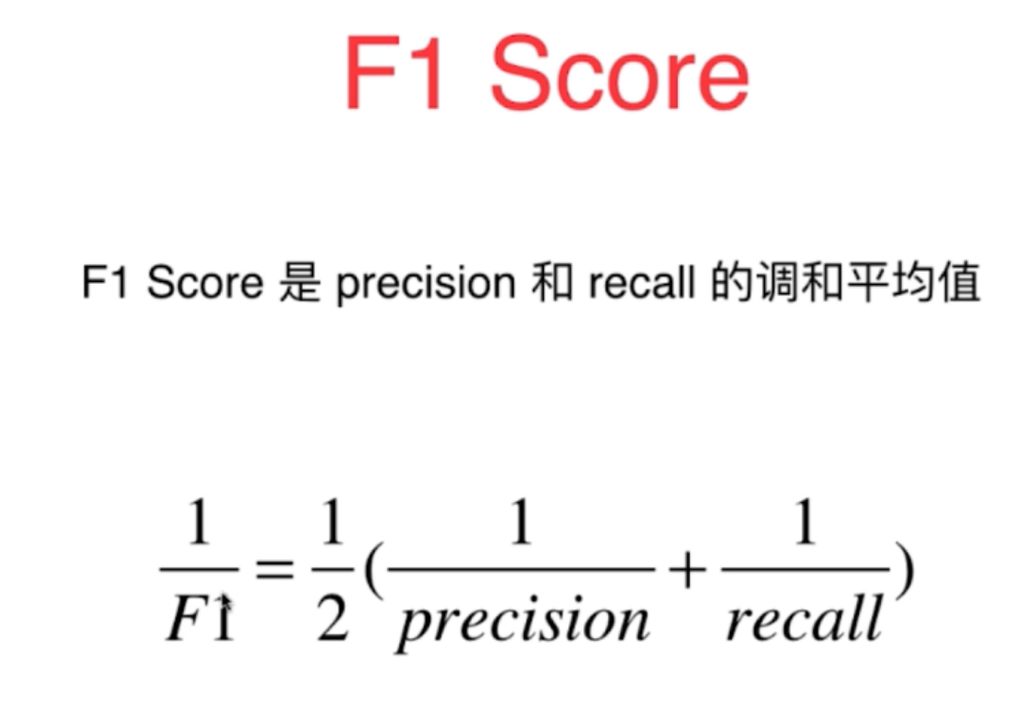
6、也有一些情况并不是只关注精准率和召回率中的一个,而是需要
同时兼顾精准率和召回率,这个指标有一个叫做F1score,它的指两者的调和平均值,而非简单的求取平均。它的特点是如果精准率和召回率一个特别大,一个特别小,则输出的F1 score则比较小,它可以防止正常平均时的一些判断偏差的情况,比较好的兼顾两者的共同大小。

图
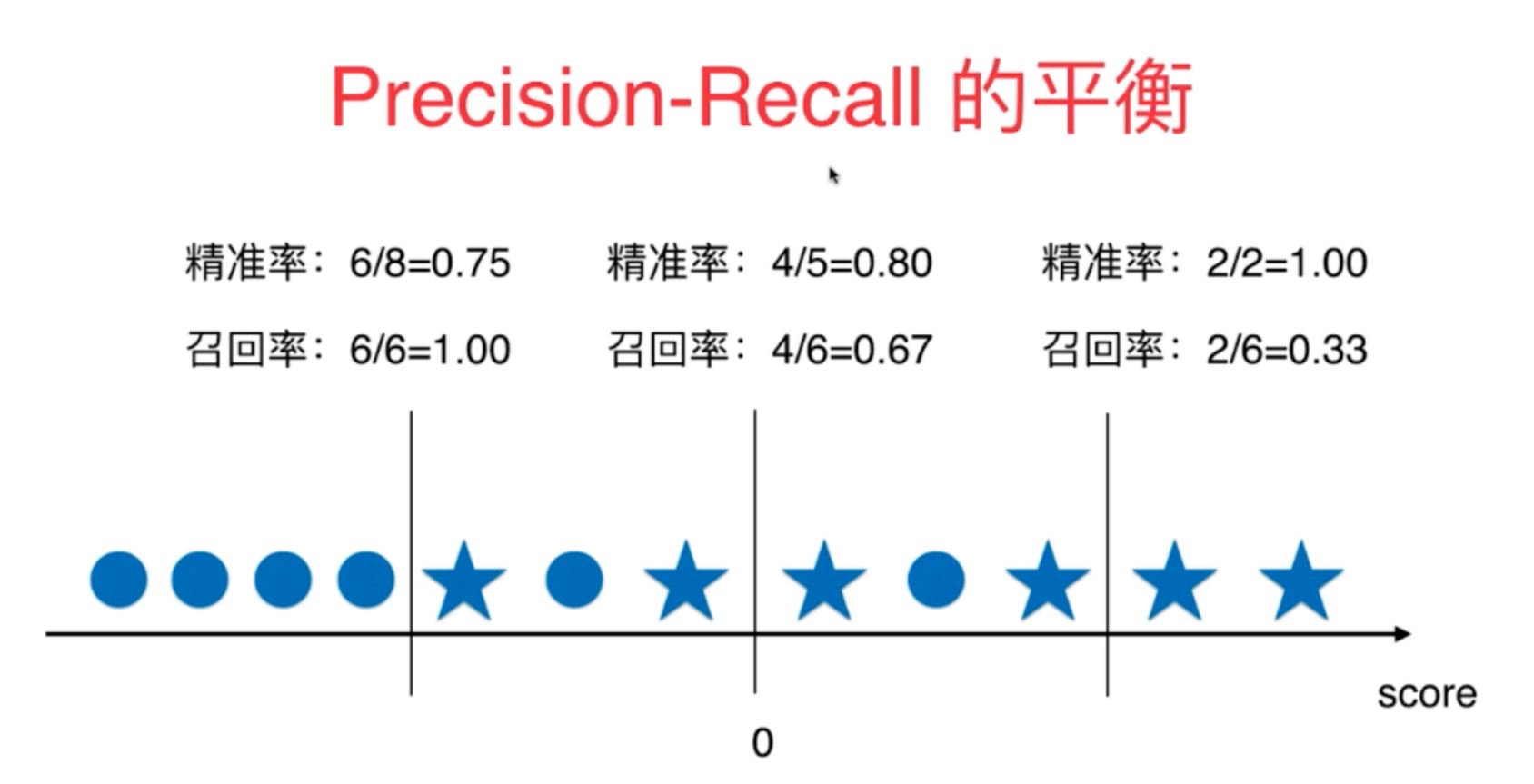
7、
精准率和召回率在机器学习算法的分类算法中是存在矛盾的,随着判断score判断阈值的提高,精准率会不断地增大,而召回率是不断减小的。
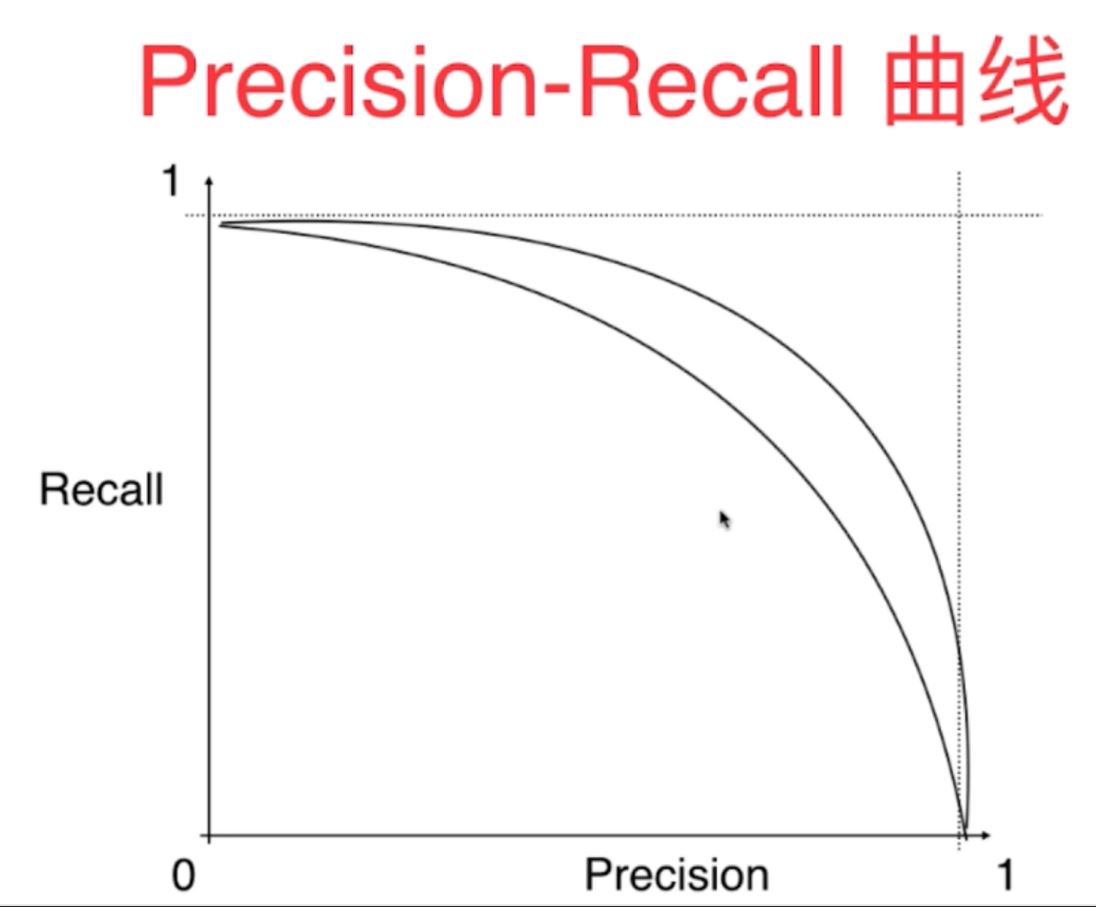
8、
PR曲线,即precision-recall curve,它可以表示出机器学习分类算法的召回率随着精准率变化的曲线,通过对比可以看出不同算法的好坏,一般与x/y轴所围成的面积越大,其综合性能也就越好。
9、
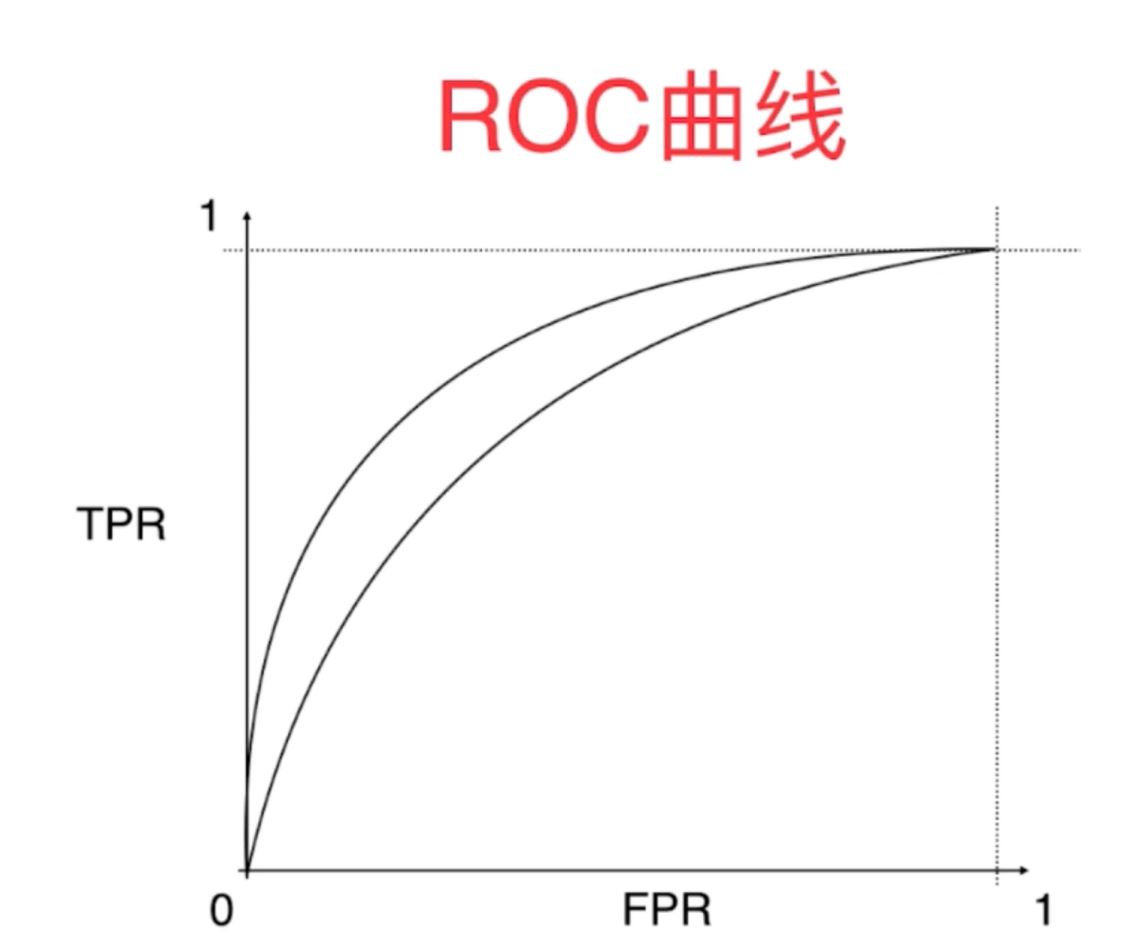
ROC曲线,描述TPR和FPR之间的关系,是统计学上经常用到的曲线和指标曲线,其主要的指标是
ROC曲线与x轴所围成的面积roc-au_score,面积越大,则模型越好。另外,ROC曲线对于具有极偏数据是不敏感的。